布隆过滤器
布隆过滤器
参考文章:
- 布隆过滤器,这一篇给你讲的明明白白-阿里云开发者社区 (aliyun.com)
- 布隆过滤器,位图,HyperLogLog | Rico’s Blog (hogwartsrico.github.io)
- 海量数据判重——布隆过滤器(Bloom filter)与Bitmap对比_tick_tokc97的博客-CSDN博客
- 数据结构与算法必知— Bitmap位图与布隆过滤器 - 简书 (jianshu.com)
定义
布隆过滤器(Bloom filter)是一个高空间利用率的概率性数据结构,由Burton Bloom于1970年提出。实际是基于位图来实现的一种数据存储结构,用来判断某个元素(key)是否在某个集合中。和一般的位图不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一个标志,用来判断key是否在集合中。
原理
布隆过滤器对一个对象使用多个哈希函数。如果我们使用了 k 个哈希函数,就会得到 k 个哈希值,也就是 k 个下标,我们会把数组中对应下标位置的值都置为 1。布隆过滤器和位图最大的区别就在于,我们不再使用一位来表示一个对象,而是使用 k 位来表示一个对象。这样两个对象的 k 位都相同的概率就会大大降低,不仅能够解决单哈希容易造成冲突的问题,还能有效减少内存空间的使用。
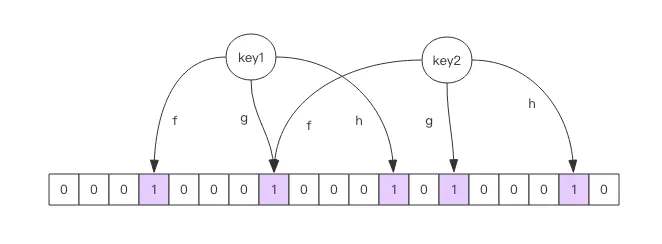
优缺点:
- 优点:不需要存储key,节省空间
- 缺点:
- 假阳性,存在一定的误判
- 添加过的元素无法删除
误判
布隆过滤器的误判是指:多个对象经过哈希之后将某个相同位置的bit位 置为1,这样无法判断是哪个对象产生的,因此误判的根源在于相同的 bit 位被多次映射且置 为1。
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。
特点:一个对象如果判断结果为存在的时候该对象不一定存在,但是判断结果为不存在的时候则一定不存在。
应用场景
- 防止缓存击穿
- URL去重
- 垃圾邮件识别
- 大集合中的重复元素
- ……
与Bitmap的区别
假设我们有1千万个(不重复、未排序)的整数需要存储,每个整数的大小范围是1到1亿,那么我们的Bitmap就需要需要1亿个连续长度的bit
空间不随集合内元素个数的增加而增加,比如上面这个例子不管数量是1千万还是2千万,都不会影响空间大小
但是不足之处也同样明显:空间随集合内边界元素的扩大而扩大,比如上面这个例子当范围改变时,集合大小就需要跟着改变
Bitmap用于处理非数字类型的时候,对内存空间的占用较大,效果并不理想,使用布隆过滤器更为合理。
 wechat
wechat alipay
alipay




